The False Miracle
Everyone has seen that test for a feature that was supposed to change everything and generate a billion in revenue. The test runs for two months. The team is anxious. When it's time to present the results, the big surprise: the p-value came in at 0.06, just above the traditional 0.05 threshold.
The mood gets heavy. Many resources, time, and hopes invested in that brilliant idea seem lost. Then, someone raises their hand and brings the solution, the light at the end of the tunnel, the salvation of the billion.
"What if we let the test run for one or two more weeks? Just to see if it finally 'nails it'?"
Absolute silence precedes slow applause. Everyone pauses to appreciate the most brilliant idea that appeared in that company. Two weeks later, the "miracle" happens: the p-value drops to 0.048. The feature is approved, the hero promoted. Now it's just waiting for the billions to come in.
Everything seems perfect. But what may have occurred is the materialization of a false positive. How is this possible? To explain "counter-intuitive" statistical results, it's always good to turn to a classic: the Monty Hall Problem.
The Monty Hall Problem and the Illusion of Choice
You may not know the Monty Hall Problem by heart, but you've certainly seen that 21 (blackjack) movie scene or heard a math-enthusiast friend trying to explain it (sometimes it's strange to realize how real this is and that it's happened in your life).
The classic problem consists of a TV host, a player, three doors, two goats, and a car. The player chooses a door. The host, who knows what's behind each door, opens one of the unchosen doors, always revealing a goat. He then turns to the player and offers: "Do you want to switch to the other door that remains closed?"
Intuitively, it seems to make no difference. Two doors remain, so the chance of the prize being behind each one would be 50%, right? Wrong. This perception ignores the crucial fact: the host doesn't open a door randomly; he opens a door with privileged information about where the prize is.
The Math Behind the Opened Door
When analyzing only the second decision (switch or not), we disregard the first. Breaking it down:
- Initial choice: You have a 1/3 chance of picking the car and a 2/3 chance of having picked a goat.
- Host's action: He always opens a door with a goat from the two you didn't choose. If you initially picked a goat (2/3 probability), he's forced to open the only other goat door, leaving the car inevitably at the remaining door.
- Final decision: Therefore, if you switch, you invert the initial probabilities. Switching gives you a 2/3 chance to win; staying gives you only 1/3.
Let's put the probabilities on paper using Bayes' Theorem. The beauty lies in how a single piece of information completely transforms the probabilistic scenario.
Defining the events:
- C₁, C₂, C₃: Car is behind door 1, 2, or 3 (initial probability of each: 1/3)
- E: Observed evidence - host opens door 3 with a goat
- You initially chose door 1
We want to calculate:
- $P(C_1|E)$: Probability the car is behind door 1, given that we saw door 3 open
- $P(C_2|E)$: Probability the car is behind door 2, given that we saw door 3 open
Applying Bayes' Theorem:
$$P(C_i|E) = \frac{P(E|C_i) \cdot P(C_i)}{P(E)}$$Calculation of conditional probabilities $P(E|C_i)$:
-
If the car is behind door 1 (your initial choice):
- The host can open door 2 or 3 (both have goats)
- $P(E|C_1) = 1/2$ (50% chance of opening exactly door 3)
-
If the car is behind door 2:
- The host is forced to open door 3 (can't open door 2 with the car, nor your door 1)
- $P(E|C_2) = 1$ (100% certain)
-
If the car is behind door 3:
- The host would never open the door with the car
- $P(E|C_3) = 0$ (impossible)
Total probability of the evidence P(E):
$$P(E) = P(E|C_1)P(C_1) + P(E|C_2)P(C_2) + P(E|C_3)P(C_3)$$ $$P(E) = \left(\frac{1}{2}\right) \cdot \frac{1}{3} + \left(1 \cdot \frac{1}{3}\right) + \left(0 \cdot \frac{1}{3}\right) = \frac{1}{6} + \frac{1}{3} + 0 = \frac{1}{2}$$Final results - the Bayesian update:
$$P(C_1|E) = \frac{\frac{1}{2} \cdot \frac{1}{3}}{\frac{1}{2}} = \frac{1}{3} \quad (33.3\%)$$ $$P(C_2|E) = \frac{1 \cdot \frac{1}{3}}{\frac{1}{2}} = \frac{2}{3} \quad (66.7\%)$$What this means in practice:
Your initial door maintains the original 33.3% probability. The remaining door doubles its probability to 66.7%. The host's action is not neutral; it transfers probability from the door he opens (which goes to zero) to the only other door he couldn't open.
Computer simulations confirm these mathematical results, consistently showing that switching results in approximately 66.7% wins, while staying with the initial choice results in only 33.3%.
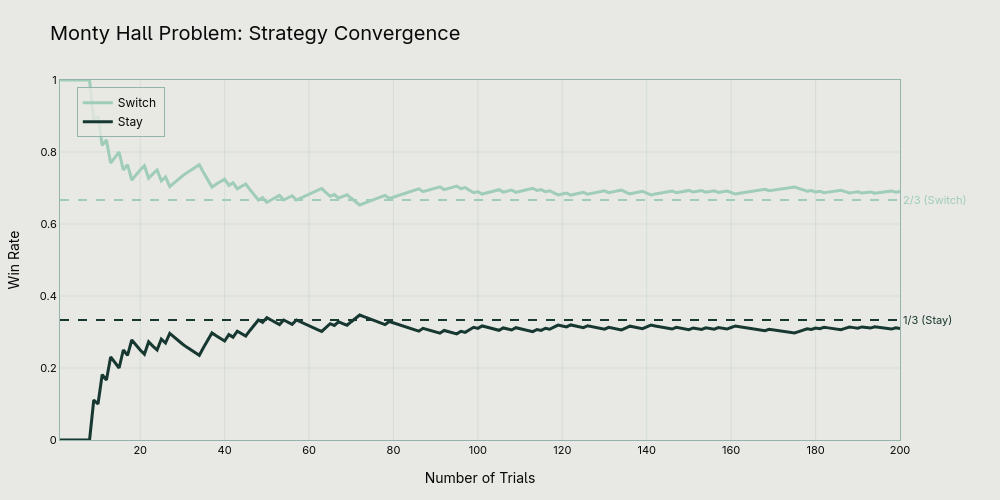
From Casino to Laboratory
Now that we understand how statistics can defy our intuition, let's return to our hero. After this epiphany, he realizes that his act of "running it a bit longer" created a situation analogous to the Monty Hall Problem.
In the analogy:
- The host (with privileged information) is our hero who decides to stop or continue the test.
- The player is the A/B test itself.
- The prize is the correct rejection of the null hypothesis (discovering a real effect).
- Opening a door is equivalent to "peeking" at the results before the planned end and making a new decision (stop or continue).
In doing so, he wasn't just giving the test "another chance." He was changing the rules of the statistical game that had been planned.
The Two Types of Error and the "Peeking Problem"
Every A/B test is designed with pre-defined parameters:
- Type I Error (α - False Positive): The probability of declaring an effect when none exists (usually set at 5%).
- Type II Error (β - False Negative): The probability of failing to detect an effect that exists.
- Test Power (1-β): The ability to detect an effect if it exists (usually 80% or 90%).
- Sample Size (n): Calculated based on the above parameters and the minimum detectable effect (MDE).
When you "peek" at intermediate results and decide to extend the test based on what you saw, you're effectively conducting multiple sequential tests on the same hypothesis. This dramatically inflates the Type I Error rate. It's called the "Peeking Problem."
The math is unforgiving. Each extra "peek" increases your chances of finding a false positive:
| Number of "Peeks" at the Test | Real Chance of a False Positive (Real α) |
|---|---|
| 1 (only at planned end) | 5% |
| 2 | ~8% |
| 5 | ~14% |
| 10 | ~19% |
| 20 | ~25% |
| Continuous Monitoring | Can exceed 30%+ |
In our hero's case, by peeking at week 8 and deciding to continue, he raised his real α to approximately 8%. The p-value of 4.8% he found at week 10, therefore, was no longer statistically significant in the new context. The "miracle" was actually a statistical mirage.
Conceptual Validation: The Monty Hall analogy is useful for illustrating how additional information (the opened door / the decision to continue) alters the interpretation of a probability. However, the statistical mechanism is different. In the "Peeking Problem," the increase in Type I Error comes from the increase in the number of comparisons (tests) performed, a phenomenon well described by multiple comparison correction. The underlying principle, however, is the same: violating the assumptions of the experimental design (in this case, the fixed stopping rule) invalidates the conclusions.
Simulations demonstrate how this mechanism works: in A/A tests (with no real difference between groups), about 25-30% cross significance at some point when continuously observed, despite only 5% being significant at the planned end.
Simulation Code
class ABTestSimulator:
@staticmethod
def run_aa_test(total_n: int = 10000, checks: int = 20, alpha: float = 0.05) -> Tuple[bool, bool, List[float]]:
group_a = np.random.normal(0, 1, total_n)
group_b = np.random.normal(0, 1, total_n)
p_values = []
peek_significant = False
for i in range(1, checks + 1):
current_n = int(total_n * i / checks)
_, p = stats.ttest_ind(group_a[:current_n], group_b[:current_n])
p_values.append(p)
if p < alpha:
peek_significant = True
final_significant = p_values[-1] < alpha
return peek_significant, final_significant, p_values
sim = ABTestSimulator()
n_sims = 10000
crossed, final = 0, 0
for _ in range(n_sims):
is_peek, is_final, _ = sim.run_aa_test()
if is_peek: crossed += 1
if is_final: final += 1
print(f"Alpha-crossing rate (Peeking): {crossed/n_sims:.1%}")
print(f"Final significance rate: {final/n_sims:.1%}")The Winner's Curse: When Even Real Effects Deceive You
The peeking problem doesn't just inflate false positives, it also systematically inflates the observed effect size of results that do pass the significance threshold. This phenomenon, known as the "winner's curse," is arguably more damaging in practice than Type I error inflation.
When you stop a test early (or extend it until significance is reached), the observed effect at that stopping point is not a random sample of the true effect, it's conditionally selected for being large enough to cross the significance threshold at that particular moment. Noise that happened to push the estimate upward is what triggered the stopping decision in the first place.
This is not just a theoretical concern. Etsy's engineering team published a detailed analysis of how the winner's curse affects their A/B testing program, showing that naively trusting the observed lifts of winning experiments leads to substantial overestimation of real business impact. Their mitigation strategy uses Bayesian shrinkage estimators to discount reported lifts toward a prior, producing more realistic effect size estimates.
The winner's curse is worst when statistical power is low, exactly the conditions that arise when tests are underpowered or stopped early. Studies powered between ~8% and ~31% are likely to see their initial effect estimates inflated by 25% to 50%. In A/B testing, where minimum detectable effects are often optimistically small and sample sizes are chosen under budget constraints, this range is not uncommon.
Even when an extended test finds a real effect, the observed magnitude at the stopping point should be treated with skepticism. The true effect is almost certainly smaller.
How to Escape the Statistical Russian Roulette
Now, armed with knowledge, our hero (now a true experiment scientist) seeks the right solutions. There are well-established paths:
The "Classical" Frequentist Approach (The Simple Gold Standard)
- Calculate the sample size (n) BEFORE starting the test, based on desired α, power (1-β), and MDE.
- Set a single stopping rule: run the test until you reach exactly n.
- Don't look at the results during execution.
- Make ONE decision at the end, based on the p-value calculated once.
If You Really Need to Look (Sequential Methods)
For those who need more agility, there are formal methods:
- Bonferroni Correction: Divide α by the number of planned peeks (e.g., 5 peeks → use α=0.01 at each). Problem: Very conservative, drastically reduces test power.
- Sequential Procedures (O'Brien-Fleming, Pocock): Adjust significance thresholds (stricter at the beginning, closer to α at the end) to control overall error. They're the statistically valid solution for tests with planned interim analyses.
- Always-Valid P-Values (e.g., mSPRT): Advanced methods, such as the modified Sequential Probability Ratio Test, that calculate a measure of evidence that remains valid no matter when you look.
- Bayesian Approach: Continuously updates posterior probabilities based on data. Allows well-defined stopping rules (e.g., stop when P(effect > X) > 95%), but requires careful definition of a prior.
Correction for Multiple Comparisons
The problem gets worse with multiple metrics or variants. For 20 metrics tested with α=5%, the chance of at least one false positive jumps to ~64%!
- Benjamini-Hochberg Method: Controls the False Discovery Rate (FDR), a less conservative approach than Bonferroni.
From Betting to Science
Extending an A/B test "just a bit more" based on intermediate results is not an act of perseverance. It's the statistical equivalent of doubling down on a losing hand at the casino, hoping the next card will change your luck. The odds are structurally against you.
Rigorous experimentation is what separates data-driven decisions from bets disguised as analysis. Master the fundamentals, plan your test in advance, and choose the appropriate sequential analysis method if agility is critical.
Thus, you'll stop being a player in the casino of randomness and become a true scientist.
References
- How Not To Run an A/B Test. evanmiller.org.
- A/B Testing and the Peeking Problem - Code Notebook. Interactive Google Colab notebook with all code examples used in this article.
- 21 (Movie Scene) - The Monty Hall Problem Explained. Famous scene from the film "21" (2008) demonstrating the Monty Hall Problem.
- Behind Monty Hall's Doors: Puzzle, Debate and Answer. The New York Times, 1991.
- The Monty Hall Problem: A Study. MIT Research Science Institute.
- Peeking at A/B Tests: Why it matters, and what to do about it. Johari, R., Pekelis, L., & Walsh, D. J. (2017). Proceedings of the 23rd ACM SIGKDD.
- Bringing Sequential Testing to Experiments with Longitudinal Data (Part 1): The Peeking Problem 2.0. Spotify Engineering Blog, 2023.
- Etsy Engineering. Mitigating the Winner's Curse in Online Experiments. 2025.
- Button, K. S., et al. (2013). Power failure: why small sample size undermines the reliability of neuroscience. Nature Reviews Neuroscience.
- Benjamini, Y., & Hochberg, Y. (1995). Controlling the false discovery rate: a practical and powerful approach to multiple testing. Journal of the Royal Statistical Society.
- O'Brien, P. C., & Fleming, T. R. (1979). A multiple testing procedure for clinical trials. Biometrics, 549-556.
- Wald, A. (1945). Sequential tests of statistical hypotheses. The Annals of Mathematical Statistics, 16(2), 117-186.